During the development of our Simple Login Protect for WordPress, we studied some other open source plugins to understand what they were doing to anonymize IP Address, a requirement of GDPR and LGPD.
The IP is considered a sensitive information by the two laws and it is necessary to ask the user’s consent before storing that information.
An alternative to not depending on consent is to anonymize the information before using it. The legislation is specific that the algorithm can not be reversed identifying the real user.
The IP is not a direct way of knowing the person on the other side, but if the user identifies himself at some point in the process (i.e.: when making a purchase), we could associate all the previous actions of that IP (i.e.: all searches for products for example) to the user now identified, which would be a violation.
This impacts Web Analytics tools, such as Google Analytics, but also Web Firewall and Security Tools in general, as they usually store this information next to the navigation data.
When we looked at the tools, we saw that some that called themselves in conformity with GDPR, adopted the IP Hash as a means of anonymizing the IP Address.
A hash function receives a word at the input, in this example the IP and calculates a sequence from it, usually represented in hexadecimal format.
The first prerogative of the Hash function is that, based on the result obtained, it should not be possible to obtain the input value “easily”, emphasizing the easily.
In the example below, the result 201 could be from the word SECRET, ESRCTE, TERCES or any combination, or even other unrelated letters and even words with other sizes.
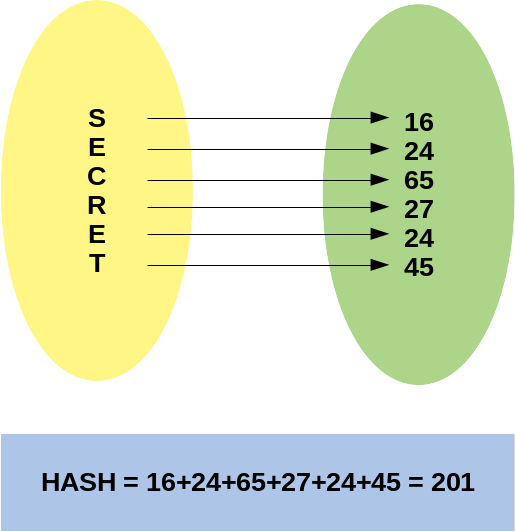
The second prerogative of Hash algorithms is that, given an input, the calculated output is always the same, for example, Hash SHA1 from IP 192.168.0.1 will always be: 24682ccf0d260b650fd5891de58d141b1fe8c316, no matter how many times we use it, as I explained in that other article .
Well, back to the original problem, what we saw implemented were tools calculating the IP Hash and storing it in a table.
It turns out that the hash of a value does not leave that value anonymous, so the emphasis on “easily” a few paragraphs ago.
The problem is that the IPv4 numbering space is limited in computational terms, there are only 32 bits of addressing, usually represented by 4 numbers, the famous 192.168.0.1 numbering that we know.
This gives us about 4 billion possible IPs (256 ^ 4 = 4,294,967,296 to be exact), it seems a lot, but to calculate the Hash of those 4 billion IPs, it can be done in a few hours with a regular computer.
In practice, it is possible to revert a stored hash to the original IP in a few hours at most using a dictionary attack (we say dictionary attack because we previously knew all possible combinations of IPs, this is our “dictionary” for calculation).
If it is reversible, it is not anonymized, so it does not comply with GDPR
A few hours to revert an IP can be a bit much, so let’s go to another form of the same attack:
Rainbow Tables
Rainbow Tables are pre-calculated hash tables, they are used to make dictionary attacks faster.
For our case, we must calculate the hash of all IPs and leave it pre-calculated and stored.
They are then stored with the ordered Hash, that is, a Rainbow Table of the IPs from 192.168.0.1 to 192.168.0.9 will look like this, see that the Hashs are in alphabetical order:
1dcca23355272056f04fe8bf20edfce0 192.168.0.5 26ab0db90d72e28ad0ba1e22ee510510 192.168.0.2 48a24b70a0b376535542b996af517398 192.168.0.4 6d7fce9fee471194aa8b5b6e47267f03 192.168.0.3 7c5aba41f53293b712fd86d08ed5b36e 192.168.0.9 84bc3da1b3e33a18e8d5e1bdd7a18d7a 192.168.0.7 9ae0ea9e3c9c6e1b9b6252c8395efdc1 192.168.0.6 b026324c6904b2a9cb4b88d6d61c81d1 192.168.0.1 c30f7472766d25af1dc80b3ffc9a58c7 192.168.0.8
That is, given the hash 6d7fce9fee471194aa8b5b6e47267f03, we would quickly find the IP number 192.168.0.3 that originated the same.
This can be stored in a database with an index for faster searching, or created a specialized database (i.e.: using binary tree) for higher performance and less storage space.
Remembering that the IP, by the IPv4 protocol has only 32 bits and an MD5 Hash has only 128 bits, we need 160 bits, or 20 bytes for each record.
Considering all IPv4 numbering of 4 billion addresses, we need about 80 Gbytes to store the entire range. If we use a few control bytes and use an index we can reach about 100 GB on disk using a common DBMS.
A regular DBMS would make this query in a few milliseconds, that is, given a hash of an IP that should be anonymized, it is possible to be reversed in a simple and quick query.
That said, we cannot in any way consider that an IP hash is anonymizing an IP.
If it is reversible, it is not anonymous and does not conform to GDPR
Also for other sensitive documents, such as SSN (Social Security Number) Phone numbers, city names, all within a known and predictable range, are sensitive to dictionary attacks and rainbow tables.
The SSN, for example, has only 9 digits, there are only 1 billion possible combinations, 4 times less than IPv4.
Therefore, the use of 20 GB of disk space would allow reversing the Hash of any SSN in microseconds, using a few IOPS, a base with 100 thousand customers would be converted from Hash to SSN in a few minutes on a common computer.
If you need to store this data, consider using common encryption with a symmetric key or Tokenization, at least no one will confuse believing that the data is confidential when it is not.
If you need to anonymize this data, consider other methods like Data Blurring or Masking.
References and other readings: